


你好,世界!
这是本站的第一篇正式文章,介绍站名的由来是个相当不错的选择!
“绁堢シ”三个字确实容易让人摸不着头脑,甚至让人乍一看以为是日语,毕竟其中确实有日文符号。但实际上这并不是日文,甚至也不是中文。虽然它由汉字和片假名组成,但实际上是地地道道的乱码,与众所周知的“锟斤拷”的原理相似。
在进入正题之前,先插播一个小趣闻,这也是笔者开始对字符编码感兴趣的契机。
卧槽!这是什么??
当年学计算机网络,学到http时,教材上提到可以尝试使用telnet连接web服务器,手动发送http请求报文。
笔者当即陷入震惊,“卧槽!还有这种操作?!”
事不宜迟,马上开始实践!我去浏览器里边随便复制来一段http请求头,大致内容如下
GET / HTTP/1.1
Host: www.cs.zju.edu.cn
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:139.0) Gecko/20100101 Firefox/139.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Language: zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2
Connection: keep-alive
Cookie: SESSION=580b1268-7f32-4342-abd4-937c79aeac63
Upgrade-Insecure-Requests: 1
Priority: u=0, i
Pragma: no-cache
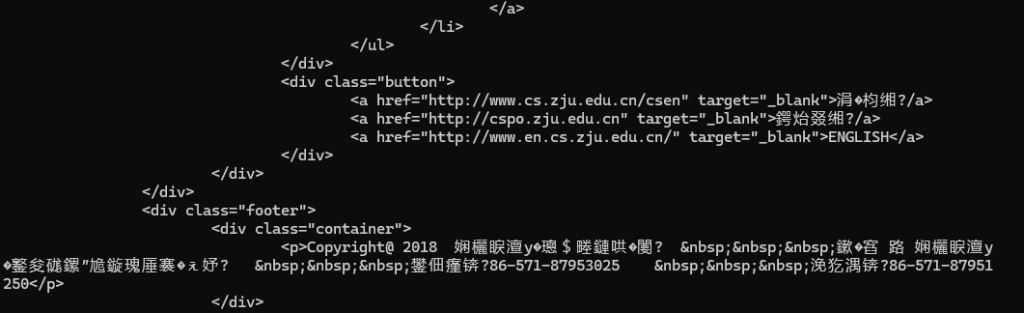
Cache-Control: no-cache如你所见,这是浙江大学计算机学院的官网,虽然不知道他们为什么不使用https,但既然如此,我正好直接拿来用hehehe。
telnet 连接"www.cs.zju.edu.cn",指定端口80。很顺利地连上了。


接下来就是发送请求报文了,没什么可说的,直接把上面的请求头复制粘贴。
正当我期待收到一个html格式的文档时,意外出现了。
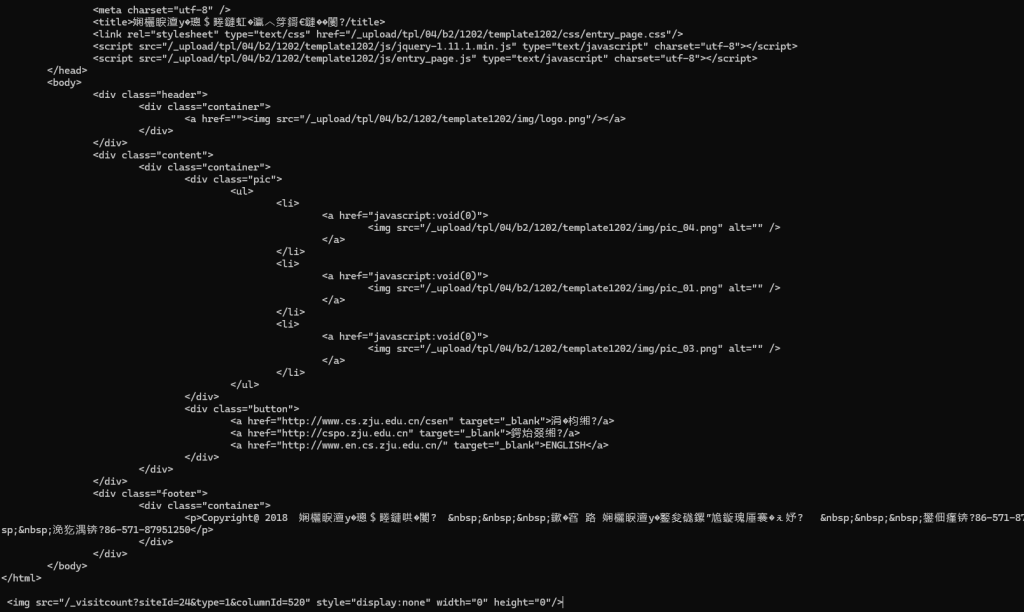
这无论怎么看都是一个正常的html文档,但其中却掺杂着许多面目狰狞的生僻字。
虽然我知道浙江大学定然有深厚的文化底蕴,但用这种火星文来传达含蓄的感情实在有些不体面。
一定是哪里出错了吧?遇事不决问百度,度娘给出了如下解释。
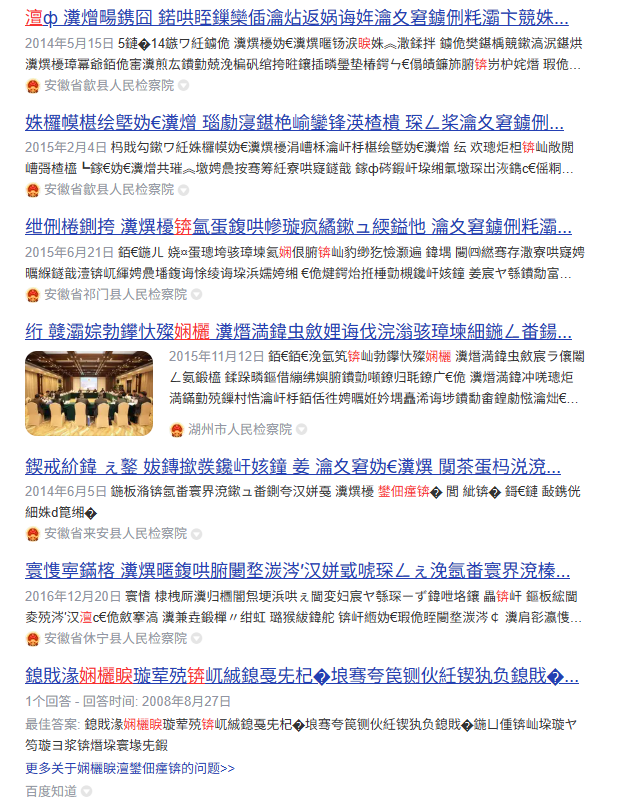
看来在我的认知之外,还有另一种使用汉字的语言在中国被大规模使用。
开个玩笑。总之历经一番波折,我终于知道这些东西是什么玩意了,总结一句就是
“以UTF-8格式编码的字符被错误地当作GBK编码来解码所得到的乱码”
简单来说,汉字作为表意文字,在计算机中储存和传播都相当不容易,需要约定一种编码字符集。
举个例子:
标准A规定 AB='我',CD='爱',EF='你'
标准B规定 ABC='滚',DEF='蛋'
上面的情况相当于:有人使用标准A向心上人表白,而对方按照标准B解读了!
表白能不能成我们暂且不得而知,不过至少现在肯定是要出大问题了。

回到现实,例子中的标准A和标准B差不多就是GBK和UTF-8的关系。
那么,UTF-8和GBK又是什么?
UTF-8
现代计算机技术发源于西方,而实际上英语又是一种相当简单的语言(它只有26个字母),所以对于计算机来说,它只需要为数字0-9和26个字母的大小写以及其它一些必须的符号编码,就能储存大多数的英语文字信息了。
ASCII(美国信息交换标准代码) 就是这样一种解决方案,它仅使用了0x00-0x7F共128个编码,就能覆盖大多数英文文字资料。
但是计算机这种好东西,当然不只有西方人能用。世界各国为了在计算机中表示自己的文字,也进行了许多尝试。如今在我们周围,就存在着许多成熟的编码字符集,比如GBK、GB2312、Big5、Shift_JIS等等。
但如果各国都只使用自己的标准,这些标准又互不兼容时,“表白失败”的例子就会层出不穷。
为了增强字符编码的通用性,Unicode(“统一码”)诞生了。
它的目标是容纳世界上所有语言的文字和符号,为每个字符分配一个独有的编码。
这些编码显然会很长(4字节),如果计算机储存的字符每个都占用4字节,那么对于出现频率更高的英文字符来说就太不公平。反映到结果上,就是计算机为了储存字符浪费了太多空间,所以Unicode在实际的应用中,会使用变长编码。
Unicode的实现方法有UTF-8、UTF-16、UTF-32。其中最广泛使用的就是UTF-8。
UTF-8是如何把Unicode储存在计算机中的呢?
首先要知道UTF-8是一种变长编码,最多支持4个字节,具体规则如下:
- 一个US-ASCIl字符只需1字节编码(Unicode范围由U+0000~U+007F)。
- 带有变音符号的拉丁文、希腊文、西里尔字母、亚美尼亚语、希伯来文、阿拉伯文、叙利亚文等字母则需要2字节编码(Unicode范围由U+0080~U+07FF)。
- 其他语言的字符(包括中日韩文字、东南亚文字、中东文字等)包含了大部分常用字,使用3字节编码。
- 其他极少使用的语言字符使用4字节编码。
具体编码规则
- 单字节:首字节的第一位为0,对于所有ASCII编码(
0x00-0x7F),UTF-8编码即为ASCII编码,所以UTF-8完全兼容ASCII。 - 二字节:首字节的前三位为
110,其余字节前两位为10。 - 三字节:首字节的前四位为
1110,其余字节前两位为10。 - 四字节:首字节的前五位为
11110,其余字节前两位为10。
下面举个具体例子:
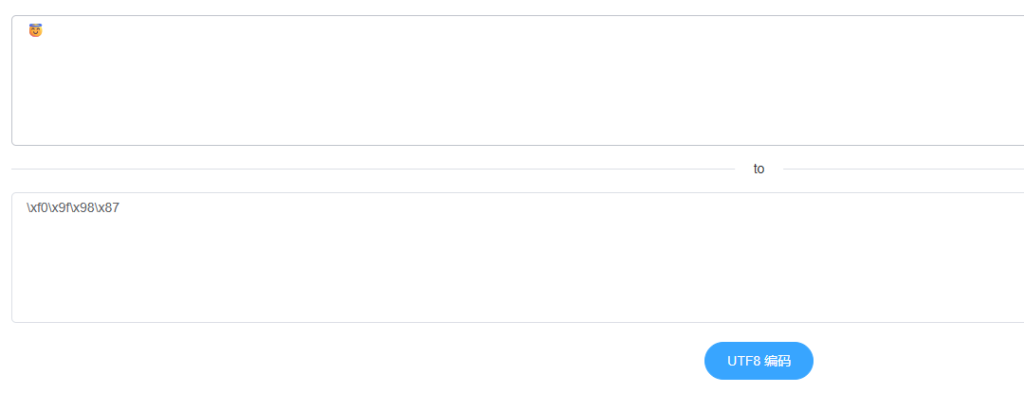
emoji表情“😇”的Unicode为0x1F607,共17位,所以应该采用四字节编码。
- Unicode:
00011111011000000111 - UTF-8:首字节
11110000第二字节10011111第三字节10011000第四字节10000111 - 16进制为
0xF09F9887
验证:
GBK
中国对汉字信息化的尝试其实很早。1980年,中国公布了国家标准《信息交换用汉字编码字符集》,也就是所谓的GB2312。
GB2312收录了6763个汉字以及683个非汉字图形字符。整个字符集分成94个区,每区有94个位。每个区位对应着一个字符。定位一个字符时,同时需要区号和位号,称为“区位码”。
下图是GB2312编码表的一部分。

GB2312已经覆盖了日常生活的绝大多数使用场景,但是在涉及到一些古籍文献以及一些生僻字和少数民族文字时,GB2312就显得不太够用。因此需要对它进行扩展。因此后来又出现了GBK(powershell使用的编码)、GB18030等支持更多字符的编码表,它们都兼容GB2312。
乱码的产生
乱码是怎么来的?如果读到这里大家应该都能猜到了。
与上面“表白失败”的例子很相似,GB使用2字节编码,而UTF-8中汉字使用3字节编码。国内GB编码十分通用,但在国际上更通用的是UTF-8。因此在某些情况下会出现乱码。
可以简单验证一下,想想浙江大学对我说了什么?
为了看看它是不是在对我表白,我们尝试还原一下。
既然乱码是错误解码产生的,那我们只需要纠正解码方式就好了!
随便找一个支持改变字符集的文本编辑工具,这里使用notepad++,将编码改为UTF-8,就能还原原始信息了。
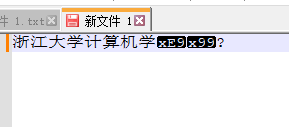
看来浙江大学并未向我表白,不过这不要紧,我们至少知道了一部分乱码产生的原因:
对于包含大量生僻字+日文韩文的乱码,大概率是按照GBK解码UTF-8编码产生的
如果反过来会怎么样呢?
在notepad++中编写一段中文内容,记得先将编码切换为GB2312(ANSI)
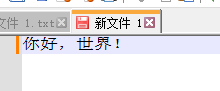
再将编码切换为UTF-8,乱码产生了!
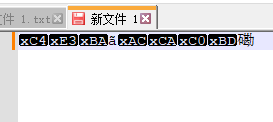
但严格意义上图并不是乱码,notepad++将无法解码的部分按16进制原样输出了。更一般的情况,这些无法解码的部分会被替换为"�",所以你很可能会看到这样的东西。
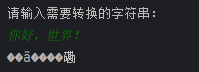
再来想想更有意思的情况,我们将上面两种情况结合一下会怎么样?
也就是说,"中文"->编码为UTF-8->按照GBK解码->编码为GBK->按照UTF-8解码->?
显然,如果原始中文信息的长度为偶数,那么最终会得到正确还原的信息,因为UTF-8和GBK对汉字的编码长度比为3:2,两个UTF-8中文编码对应着三个GBK中文编码。如果原始长度为奇数的话,由于大部分软件会将无法解码的部分替换为问号,所以会损失一部分。
反过来,"中文"->编码为GBK->按照UTF-8解码->编码为UTF-8->按照GBK解码->?
在此过程中,按照UTF-8解码时,通常会出现大量无法解码的部分,这些部分全部会被替换为"�"。
"�"的UTF-8编码为0xEFBFBD,当两个"�"连起来时,就是0xEFBFBDEFBFBD。这时候按照GBK解码会发生什么?
没错,每两个字节会变成一个中文字符,最终会变成“锟斤拷”。
验证一下
python中可以很方便地对字符串进行编解码,编写验证代码。
def gbk_to_utf8(messed_str):
"""GBK转换为UTF-8"""
byte_data = messed_str.encode('gbk', 'replace')
messed_str = byte_data.decode('utf-8', 'replace')
return messed_str
def utf8_to_gbk(str):
"""UTF-8转换为GBK"""
byte_data = str.encode('utf-8', 'replace')
str = byte_data.decode('gbk', 'replace')
return str
def main():
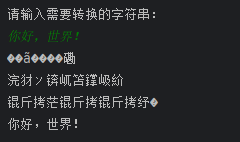
strr = input("请输入需要转换的字符串:\n")
print(gbk_to_utf8(strr))
print(utf8_to_gbk(strr))
print(utf8_to_gbk(gbk_to_utf8(strr)))
print(gbk_to_utf8(utf8_to_gbk(strr)))
return
if __name__ == "__main__":
main()
站名的由来
废话这么多,最开始的问题呢?站名是怎么来的?
“绁堢シ”一词中既有生僻汉字也有日文片假名,所以显然是UTF-8编码按照GBK解码得到的。来试试还原。
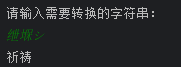
没错,就是“祈祷”。
“祈祷”是我相当喜欢的词语,而它的乱码形态又没有那么面目狰狞,因此被我当作网名一直用到了现在。
结语
此情可待成追忆,只是当时已惘然
Comments 4 条评论
我不是很懂代码,但是姑且用博文里的代码去转换了一些词语,并试着把转换的结果放进必应搜了一下。其中“死亡”转换后是“姝讳骸”,甚至搜到有一首现代诗叫这个——因为在搜索引擎里除了这三个字都是有意义的字符组合,我姑且认为这大概是真实的标题?——但是我点进去却发现它的题目只是“死亡”,于是觉得有些好笑。
@1579663459 其实例子很多,你可以多试几个
>>> bytes.fromhex('E7A588E7A5B7').decode()